全面拆解实时分析数据存储系统 Druid的数据处理与存储支持服务
引言
Druid是一个开源的、面向列式存储的、分布式实时分析数据存储系统,专为支持低延迟查询和高并发吞吐量的OLAP(在线分析处理)场景而设计。它广泛应用于实时监控、事件驱动分析、用户行为分析、广告技术等领域。本文将深入拆解Druid在数据处理与存储方面的核心架构与支持服务。
一、Druid的核心数据处理流程
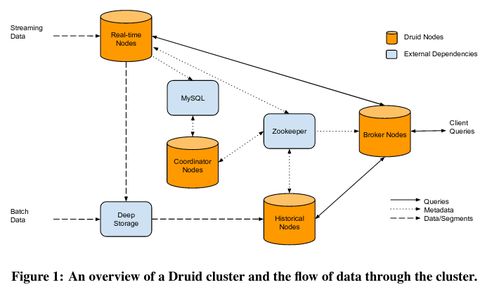
Druid的数据处理遵循一个清晰的生命周期,主要包括数据摄入、数据存储与索引、数据查询三个阶段。
1. 数据摄入
数据摄入是Druid从外部数据源(如Kafka、HDFS、S3等)获取数据的首要步骤。其摄入方式灵活多样:
- 实时摄入:通过“索引服务”实时消费Kafka等流数据,实现毫秒级延迟的数据可见性。
- 批量摄入:通过Hadoop任务或原生批量任务,从文件系统(如HDFS、S3)加载历史数据。
摄入过程中,数据会经过解析、转换(基于JSON或自定义脚本)、分区和索引,最终转化为面向列存储的、高度压缩的“段文件”。
2. 数据存储与索引
这是Druid性能优势的核心。摄入的数据被打包成不可变的“段”,每个段包含一个时间间隔内的数据,并包含三个关键部分:
- 列式存储:数据按列存储,查询时仅需读取相关列,极大提升I/O效率。
- 位图索引:为维度列创建倒排索引(位图),实现超快速的过滤和分组。
- 多层索引结构:包括时间戳、维度、指标和压缩字典,支持高效的数据定位与聚合。
数据段被分发到“数据服务器”进行存储和查询服务。元数据(如段的位置、模式)则由“协调器”和“元数据存储”(如MySQL、PostgreSQL)管理。
3. 数据查询
Druid提供了一个基于JSON的查询语言和RESTful API,支持丰富的查询类型,如Timeseries、TopN、GroupBy、Scan等。查询请求首先到达“Broker节点”,它作为查询路由,根据元数据将查询分发到相关的数据服务器,并行执行后再将结果聚合返回给客户端。
二、支撑数据处理与存储的核心服务
Druid的分布式架构由多个松耦合、各司其职的服务组成,共同支撑其强大的数据处理与存储能力。
1. 协调器服务
负责数据段的生命周期管理。它定期从元数据存储中读取段信息,并确保:
- 负载均衡:将段均匀分配到数据服务器上。
- 副本管理:根据配置的复制因子,创建数据副本以实现高可用。
- 段保留与下线:根据保留规则,自动标记和移除过期数据。
2. 索引服务
这是数据摄入的核心执行引擎,主要负责创建和销毁数据段。它由一个“Overlord”主节点和多个“MiddleManager”工作节点组成。Overlord负责任务调度,MiddleManager则运行“Peon”任务进程来执行具体的索引任务(实时或批量)。
3. 数据服务器
包括“历史节点”和“实时任务节点”。
- 历史节点:加载和提供已提交的、不可变的数据段,处理针对历史数据的查询。
- 实时任务节点:运行实时摄入任务,管理内存中的实时数据段,并定期将它们转换为不可变段并移交。
4. Broker服务
作为查询的入口和路由层。它接收所有查询请求,通过查询元数据定位数据段所在的数据服务器,将子查询并行分发,并对返回的中间结果进行合并与聚合,最终返回给用户。其内置的缓存机制(本地或分布式如Memcached)能显著提升重复查询的性能。
5. 元数据存储与深度存储
- 元数据存储:使用传统关系型数据库(如MySQL)存储系统元数据,包括段配置、任务信息等,是协调器运行的基础。
- 深度存储:使用持久化、高可用的文件存储(如HDFS、S3)作为数据段的最终“仓库”。数据段在数据服务器本地缓存,但其主副本安全地存放在深度存储中,这实现了存储与计算的分离,提升了系统的弹性与可靠性。
三、核心特性与优势
- 亚秒级查询:列式存储、位图索引和内存优化使其能够快速响应复杂查询。
- 实时与批量统一:无缝对接流与批数据源,提供统一的数据视图。
- 高可用与可扩展:无单点故障的服务架构,各层均可水平扩展以应对数据量和查询量的增长。
- 云原生设计:深度存储的抽象使其易于部署在云环境中。
四、与挑战
Druid通过其精巧的分层架构和专门化的服务组件,构建了一个高性能的实时分析数据存储系统。它将数据处理流程清晰地解耦为摄入、存储、查询,并由协调器、索引服务、数据服务器、Broker等服务协同支持,实现了低延迟、高吞吐的核心目标。
Druid也面临一些挑战,例如配置相对复杂、对多表关联查询支持较弱(更擅长星型模型)、以及在高基数维度场景下内存消耗较大等。因此,在选择Druid时,需充分考虑其适用场景与自身业务的数据模型。
总而言之,Druid是处理大规模时序和事件数据的强大工具,其数据处理与存储支持服务的设计理念,为构建现代实时分析平台提供了极具价值的参考。
如若转载,请注明出处:http://www.soooy44.com/product/20.html
更新时间:2026-06-18 05:14:34