数据库存储与索引技术演进 从存储模型到索引结构的飞跃
数据库技术作为现代信息系统的核心,其存储与索引机制直接决定了数据处理的效率与可靠性。本文将围绕存储模型与索引结构的演变,探讨其如何为数据处理和存储支持服务奠定基础。
一、存储模型的演进:从层次到关系
数据库存储模型的演变反映了数据处理需求的不断升级。早期的层次模型和网状模型虽然解决了数据存储的基本问题,但结构复杂、灵活性差。1970年,Edgar F. Codd提出关系模型,成为数据库领域的里程碑。关系模型以二维表形式组织数据,通过严格的数学理论(如集合论、谓词逻辑)保障数据的一致性与完整性。它不仅简化了数据操作,还通过结构化查询语言(SQL)实现了高度的数据独立性,使得应用程序与物理存储细节分离。
随着互联网与大数据时代的到来,非关系型(NoSQL)存储模型应运而生。文档存储(如MongoDB)、键值存储(如Redis)、列族存储(如HBase)和图数据库(如Neo4j)等模型,针对海量数据、高并发、半结构化或非结构化数据场景,提供了灵活、可扩展的解决方案。例如,文档存储以JSON或BSON格式处理数据,适合内容管理系统;而图数据库则专注于实体间的关系查询,广泛应用于社交网络和推荐系统。
存储模型的演进不仅是技术的进步,更是对数据处理多样性的响应。从关系型到非关系型,数据库系统逐渐形成了多模型融合的趋势(如NewSQL),以平衡事务一致性、可用性与扩展性。
二、索引结构的优化:加速数据检索的关键
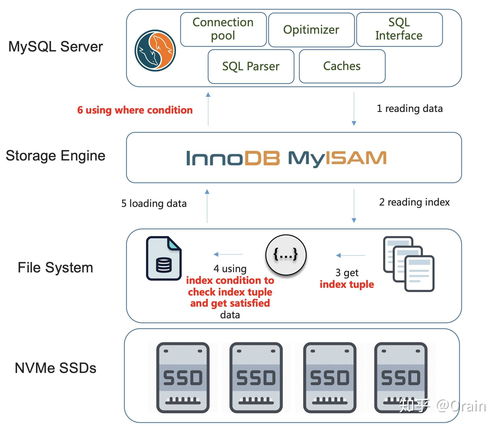
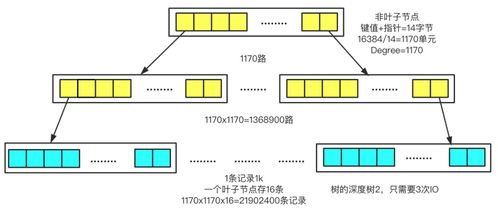
索引是数据库高效检索的“导航仪”,其结构设计直接影响查询性能。最早的索引多采用简单的线性结构,但随着数据量增长,B树(B-Tree)及其变种(如B+树)成为关系数据库的标准索引方案。B+树通过平衡多路搜索树结构,减少磁盘I/O次数,尤其适合范围查询和顺序访问,广泛应用于MySQL、Oracle等系统中。
B树在写密集场景下可能存在维护开销。为此,日志结构合并树(LSM-Tree)被提出,并被许多NoSQL数据库(如LevelDB、Cassandra)采用。LSM-Tree将随机写转换为顺序写,通过内存缓冲和后台合并操作提升写入吞吐量,虽可能牺牲部分读取性能,但在大数据环境下表现卓越。
哈希索引则以O(1)时间复杂度支持等值查询,适用于键值存储,但无法处理范围查询。倒排索引则是全文检索的核心,通过记录词汇到文档的映射,支撑了搜索引擎的高效运作。自适应索引(如数据库 cracking)和机器学习驱动的索引选择技术开始兴起,通过动态调整索引结构来适应查询负载变化。
三、存储与索引技术对数据处理服务的支撑
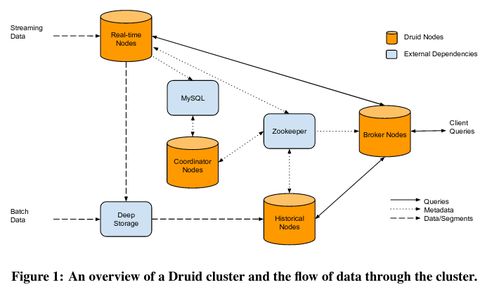
存储模型与索引结构的协同演进,为现代数据处理和存储支持服务提供了坚实基础。在云计算与分布式环境中,存储技术通过分片、复制和一致性协议(如Raft、Paxos)保障高可用与容灾;索引则借助分布式查询优化(如MapReduce、Spark索引)实现跨节点高效检索。
例如,在实时分析场景中,列式存储(如ClickHouse)结合稀疏索引,大幅提升聚合查询速度;而在物联网时序数据管理中,时序数据库(如InfluxDB)采用专有的时间序列索引,优化时间范围查询。内存数据库(如Redis)依托高速存储介质和紧凑索引结构,满足了低延迟需求。
随着硬件创新(如NVMe SSD、持久内存)和人工智能的融合,存储与索引技术将继续向智能化、自适应方向发展。量子数据库等前沿探索也可能重新定义数据处理的边界。但无论技术如何演变,其核心目标始终如一:在保障数据可靠性的让数据存取更快、更智能、更贴合业务需求。
从关系模型到多模型存储,从B树到LSM-Tree,数据库存储与索引技术的每一次飞跃,都是应对数据挑战的智慧结晶。它们不仅是技术的演进史,更是支撑数字化时代数据处理服务的坚实脊梁。
如若转载,请注明出处:http://www.soooy44.com/product/7.html
更新时间:2026-06-18 22:35:08